Redefinice IT procesů dle ITIL je v mnoha firmách chápana především jako cesta ke zprůhlednění fungování IT v organizaci prostřednictvím vymezení jasných zodpovědností a zavedením jednotných pojmů. Už to samo o sobě se ukazuje jako výrazný přínos pro schopnost exaktnějšího řízení IT, nicméně jedná se pouze o první krok, na který je potřeba navázat vytvořením prostředí, které umožňuje IT procesy měřit. Právě měření procesů slouží jako základ pro jejich zlepšování.
V následujícím příspěvku bychom se chtěli zaměřit na zkušenosti s měřením nákladů a efektivnosti automatizovaných IT procesů definovaných dle ITIL. Zaměříme se na to, jakým způsobem potřeba následného měření ovlivňuje již samotnou definici automatizovaného procesu a jak dobře se daří obecné metriky definované v ITIL převést do reálně použitelné podoby. V příspěvku uvedeme příklady konkrétních metrik měření zdrojů, nákladů a kvality z provázaných procesů ITIL Incident Management a Change Management.
Problematika měření procesů
Měření procesů je nedílnou součástí aktivit spojených se zlepšováním procesů, přičemž obecný postup zlepšování procesů by se dal rozdělit zhruba do následujících fází:

- Definice procesu
- Měření procesu
- Analýza výkonnostních indikátorů procesu
- Změna procesu
Takovýto postup pak může probíhat iterativně, čímž je minimalizováno riziko spojené s optimalizací procesů formou „velkého třesku“. Nicméně i v tomto jednoduchém postupu se skrývají určitá úskalí spočívající v „nedomyšlení“ procesu do všech důsledků. To pak vede k tomu, že je nutné proces po nasazení přepracovávat.
Naše zkušenosti s měřením procesů ukazují, že již ve fázi definice procesu je vhodné otázku měření důkladněji rozmyslet a navrhnout.
Pokud však chceme procesy měřit, musíme si uvědomit, že měření manuálních procesů je v podstatě nereálné. Výsledné hodnoty při manuálním měření totiž vykazují, kulantně řečeno, značné odchylky oproti skutečnosti. Pro získání reálných dat je potřeba měřit automatizované procesy, kdy je většina údajů pro měření shromažďována automaticky.
Nicméně i v případě automatizovaných procesů a automatického sběru údajů nám musí být jasné, jaké parametry (výkonnostní indikátory/KVI) nás budou zajímat a jak je budeme vyhodnocovat. I když nám automatizovaný proces obvykle dává určitou flexibilitu z hlediska využití standardně sledovaných parametrů, mnohé atributy pro měření je nutné explicitně doplnit a v odpovídajících místech plnit potřebnými hodnotami.
Specifika měření IT procesů
Měření IT procesů je specifické tím, že až na výjimky nemůžeme procesy hodnotit z hlediska konkrétního finančního přínosu.
Procesní rámec řízení IT služeb (ITIL) řeší toto dilema zavedením smluv o úrovni poskytování služeb (SLA), které definují klíčové výkonnostní indikátory pro IT služby. Měření operativních procesů ITIL je pak vztaženo k výkonnostním indikátorům definovaným v příslušné SLA smlouvě.
Nicméně zavedení procesů řízení IT služeb a jejich měření není u středních a velkých firem snadná a laciná záležitost, což dobře dokumentuje studie poradenské firmy Gartner Group z roku 2004, která zkoumala způsob rozložení nákladů 2,6 milionu eur v dvouletém programu na zlepšení řízení IT služeb u středně velké evropské firmy (přes 300 zaměstnanců v IT). Cílem celého programu bylo zlepšení úrovně řízení IT služeb tak, aby tým zajišťující dodávku IT služeb byl na stejné nebo i lepší úrovni než externí poskytovatelé těchto služeb.
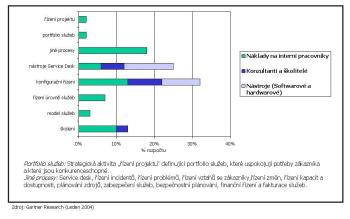
Rozložení nákladů podle jednotlivých typů (větší obrázek).
Zajímavé jsou i zkušenosti zkoumané firmy z hlediska směrování nákladů na konzultační služby. Firmě se osvědčilo využít externí konzultační kapacity především pro vzdělávání pracovníků IT a využít pomoci při definování procesů řízení IT služeb. Výsledkem toho bylo větší ztotožnění a zapojení pracovníků IT do projektu a lepší chápání jednotlivých procesů.
--------------------------------------------
ITIL (IT Infrastructure Library) je rozsáhlý, konzistentní a procesně orientovaný rámec pro oblast řízení IT služeb (ITSM - IT Service Management) založený na nejlepších zkušenostech z praxe.
Měření procesu Incident Management
Cílem procesu Incident Managementu je dle ITIL obnovení normálního fungování služby v co nejkratším čase.
Pro Incident Management je dle ITIL vhodné sledovat následující výkonnostní indikátory:
- celkový počet incidentů
- průměrný uplynulý čas potřebný k vyřešení nebo obejití incidentu
- procento incidentů zpracovaných v domluveném čase odezvy (dle SLA)
- průměrné náklady na incident
- procento incidentů vyřešených na I. úrovni podpory bez nutnosti předávat další úrovni
- počet incidentů zpracovaný na jednom pracovišti I. úrovně podpory
- počet a poměr incidentů vyřízených vzdáleně bez potřeby návštěvy uživatele.
Kromě těchto doporučených indikátorů nám připadalo účelné zavést ještě některé další:
- procento incidentů vyřešených za použití databáze známých chyb
- počet incidentů jedné třídy za uplynulé období (měsíc).
Již u druhého výkonnostního indikátoru jsme narazili na klíčovou otázku, zda do průměrného uplynulého času řešení má být začleněno i čekání na odezvu/ověření na straně uživatele. V realitě se totiž ukazovalo, že tento čas výrazně ovlivňuje celkovou dobu řešení incidentu.
Z hlediska hodnocení procesu Incident Managementu je dle našeho soudu klíčový výkonnostní indikátor č. 3 – doby odezev dle SLA. V definici procesu ve firmě ING byly předepsané časy odezev a řešení vztažené k tzv. třídám incidentů a k míře závažnosti incidentu. U tohoto výkonnostního indikátoru je však potřeba si uvědomit, že předepsané parametry se obvykle průběžně mění, a je tudíž potřeba měření vztáhnout k aktuální hodnotě parametru v okamžiku vzniku incidentu.
Z hlediska měření nákladů na vyřešení incidentu se ukázalo jako účelné kalkulovat náklady na I. a II. úrovni podpory na základě vynaložených kapacit, kdežto na III. úrovni podpory byly zpracovávány přímo finanční náklady na řešení incidentu. To ve svém důsledku komplikuje měření nákladů, neboť je potřeba převádět kapacity na finanční náklady (nebo naopak), aby bylo možné pracovat skutečně s celkovými náklady na jeden incident.
Výkonnostní indikátory 5 a 8 se sice do určité míry vzájemně ovlivňují, ale při nasazení databáze známých chyb (a jejich obejití) je účelné měřit oba dva, neboť každý z nich je používán pro hodnocení procesu z jiného pohledu. Indikátor 5 (počet incidentů vyřešených hned na I. úrovni) indikuje kvalitu pracovníků I. úrovně, kvalitu dokumentace a znalostní báze. ITIL pro tento indikátor uvádí, že kvalitní tým I. úrovně podpory by měl být schopen řešit 50 % a více incidentů. Tento indikátor je důležité sledovat z hlediska trendu – manažeři helpdesku se samozřejmě snaží dosáhnout minimálně neklesající úrovně.
Výkonnostní indikátor 8 (procento vyřešených s použitím znalostní báze) naproti tomu měří pouze kvalitu znalostní báze a kvalitu jejího použití. Tento indikátor je klíčový pro hodnocení investic do budování databáze známých chyb (a jejich obejití) a úspěšnosti procesu Problem Managementu, který dle ITIL na Incident Management bezprostředně navazuje.
Měření procesu Change Management
Cílem procesu Change Management je zajistit hladký průběh implementace schválených změn a minimalizovat počet incidentů souvisejících se zavedením změny do infrastruktury.
Klíčové výkonnostní indikátory Change Managementu dle ITIL:
- počet změn implementovaných za zvolené období celkově, dle konfigurační položky, služby atp.
- rozklad požadavků na změny dle typu
- počet úspěšně provedených změn
- počet změn vrácených zpět (např. z důvodu špatného ocenění, chybného vytvoření...)
- počet incidentů navázaných na změnový požadavek
- celkový počet změnových požadavků (včetně trendů)
- počet zrevidovaných změnových požadavků za zvolené období
- konfigurační položky (ke kterým je vztažen vysoký počet změnových požadavků)
- počet zamítnutých požadavků na změnu
- podíl požadavků na změnu, které nebyly úspěšné
- režie procesu změn dle konfiguračních položek a stavů požadavku na změny.
K těmto doporučeným výkonnostním indikátorům nám připadalo účelné doplnit:
- počet implementovaných změn dle business útvarů
- pracnost realizace změn dle business útvarů.
V případě měření procesu Change Managementu jsme naráželi na obtížnou uchopitelnost některých KVI definovaných v ITIL. Například u KVI č. 3 (Počet úspěšně provedených změn) jsme nebyli schopni najít změny (resp. jich bylo zanedbatelné minimum), které by bylo možné označit za očividně neúspěšné. Nakonec jsme dospěli k přesvědčení, že vhodnou metrikou by bylo sledovat počet navázaných defektů zjištěných při testování a incidentů vyvolaných touto změnou, ale v době realizace projektu jsme bohužel neměli k dispozici návazné informace o defektech, takže tato metrika nebyla v celé šíři poskytována.
Z hlediska hodnocení procesu Change Managementu mně osobně připadá jako velmi důležitá metrika měření režie zpracování požadavku na změnu. Z hlediska režie je celkem pochopitelně nejvyšší náročnost „úvodní analýzy požadavku na změnu“, tj. zkoumání dopadu změny a odhad pracnosti realizace. Zvláště pokud tuto režii spočítáme za zamítnuté požadavky, získáme vlastně jakési „mrtvé kapacity“, které musí oddělení IT vynaložit na řízení změn a které zdánlivě nemají žádný viditelný efekt. Zajímavou metrikou je samozřejmě také vztah režie v úvodní analýze k vlastní realizaci požadavku.
Výkonnostní indikátor č. 13 (Pracnost dle obchodních útvarů) je důležitý zvláště za situace, kdy je jednotlivým obchodním útvarům přiděleno určité procento kapacit IT z hlediska realizace operativních změn a tímto způsobem je dokumentováno, že IT vynakládá kapacity v domluveném poměru mezi byznys útvary.
Přístupy ovlivňující měření
Závěrem bych chtěl uvést jeden příklad, kdy jsou zmiňované výkonnostní indikátory do určité míry ovlivněny.
Jedním z takovýchto faktorů je zpřístupnění části databáze známých chyba a jejich obejití přímo koncovým uživatelům. Tato jinak veskrze pozitivní funkcionalita vede ve svém důsledku ke snížení počtu incidentů, což ale může být problém ve chvíli, pokud se navazující proces Problem Managementu zaměřuje dle doporučení ITIL na opakující se incidenty. Ovšem tato metrika je zkreslena, a tak mohou být Problem Managementem takovéto incidenty přehlédnuty. Řešení lze samozřejmě nalézt na straně Problem Managementu, který se musí zaměřovat také na další aspekty incidentů jako jejich závažnost dopad apod.
Autor je Professional Services Director společnosti LBMS.









































 PŘEDPLATNÉ
PŘEDPLATNÉ
 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU